Crawler
El módulo de “Recursos” te permite gestionar toda la información que tu chatbot utiliza para responder a los usuarios. Aquí podrás configurar cómo se recopila la información de tu sitio web, administrar los archivos que conforman la base de conocimientos y personalizar las instrucciones del chatbot.
Estas funciones están organizadas en tres apartados: Crawler, Archivos y Prompt. Si actualizas cualquiera de ellos tu chatbot usará los cambios a partir de la siguiente nueva conversación.
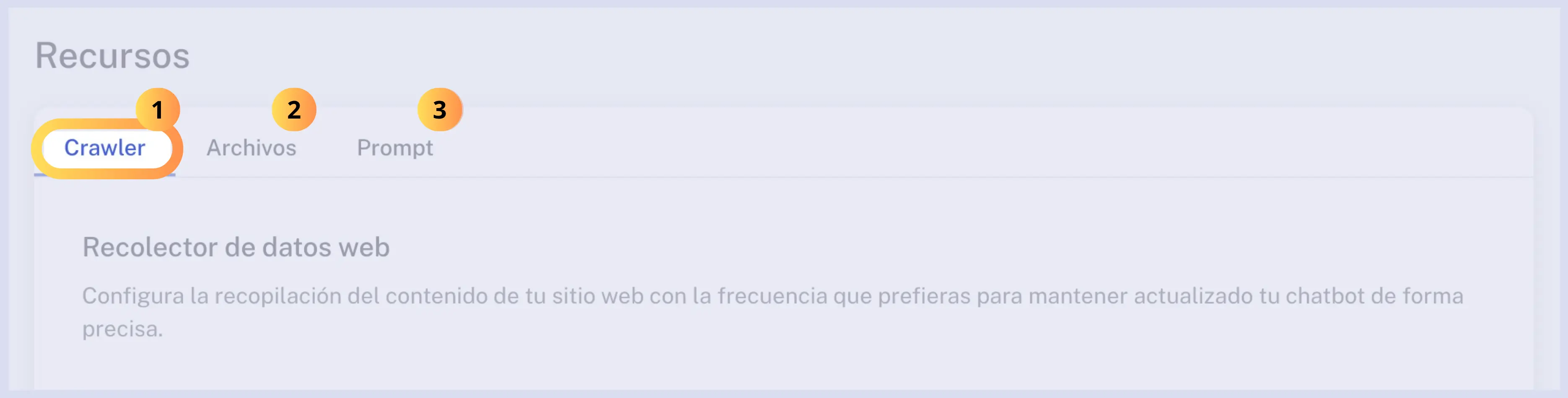
¿Cuál es la función del crawler?
El Crawler automatiza el rastreo de información desde su sitio web, ayudándole a mantener actualizada la base de conocimientos del chatbot. Puedes programar su ejecución para adaptarlo a tus necesidades.
Habilitar o desactivar rastreo
En la parte superior de esta sección se encuentra un switch que te permitirá activar o desactivar el crawler. De forma predeterminada el rastreo estará deshabilitado para prevenir consumo no contemplado de créditos.

- Si actualizas regularmente la información de tu sitio web, se recomienda mantener habilitado el rastreo y seleccionar la frecuencia con que deseas que se ejecute automáticamente.
- Si la información de tu sitio web generalmente no tiene cambios, puedes desactivar el crawler para evitar que una ejecución innecesaria consuma tus créditos.
Si ya has añadido una URL y ejecutado el crawler, verás en la parte superior de esta sección la nota “Tiene datos almacenados” en la base de conocimientos, junto con la fecha y hora de la última ejecución del Crawler. Estos datos corresponden a los archivos generados automáticamente al ejecutar el crawler en tu sitio web.
Si deseas eliminar toda la información almacenada previamente, puedes utilizar el botón “Limpiar datos”. Esta acción no se puede revertir, por lo que sugerimos tomar precauciones. En caso de limpiar datos y requerir nuevamente alimentar la base de conocimientos de tu chatbot con la información de tu sitio, será necesario ejecutar nuevamente el crawler.
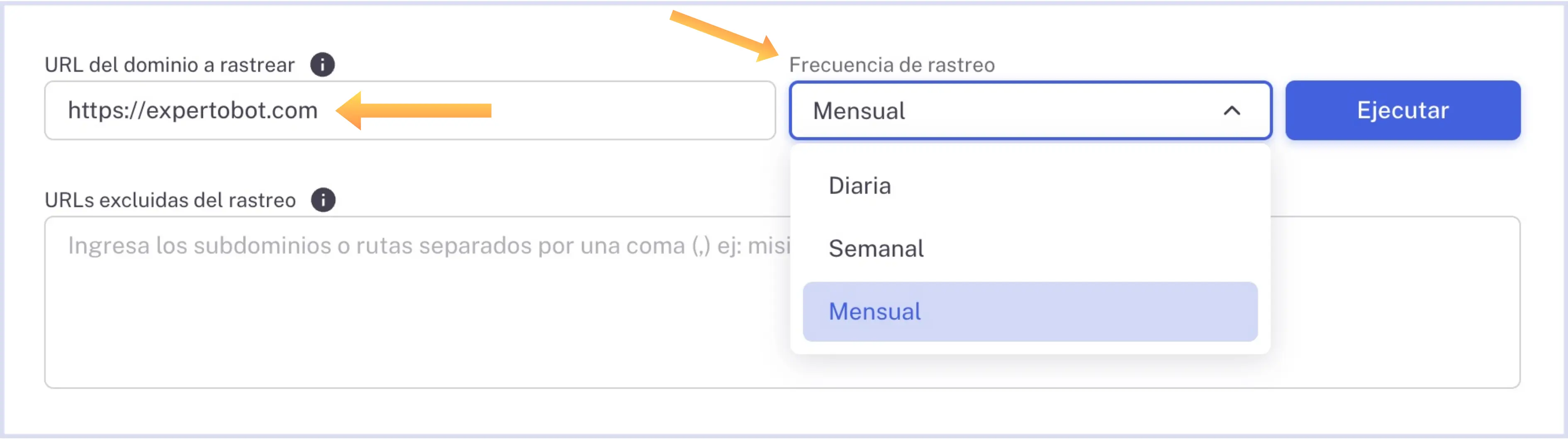
URL del dominio a rastrear
En este campo encontrarás la URL que ingresaste durante la configuración inicial de tu chatbot. En caso de haber omitido este paso el campo estará vacío y listo para que ingreses la URL si así lo requieres, la cual se utilizará para rastrear tu sitio web y obtener información de la misma.
Qué URL sirve y cuál no
El chatbot aprende de páginas que contienen contenido público legible. Por eso, no uses como fuente del crawler URLs correspondientes a:
- Perfiles o páginas de redes sociales (ej. facebook.com/tu-marca, instagram.com/...).
- Pantallas de inicio de sesión o rutas protegidas, visibles únicamente para usuarios autenticados o con permisos válidos (ej. tusitio.com/login, tusitio.com/wp-admin, tusitio.com/mi-cuenta).
- Acortadores o enlaces que redirigen sin contenido propio.
En su lugar, sí usa:
- La página pública de tu sitio (ej. tusitio.com).
- Secciones con información: tusitio.com/preguntas-frecuentes/, tusitio.com/precios/, tusitio.com/soporte/.
- Documentación pública o blog (si aporta respuestas útiles).
- Dominio: el nombre principal (j. tusitio.com).
- Sitio web: el contenido público que vive bajo ese dominio (páginas, secciones, artículos). El crawler necesita páginas con contenido, no solo el nombre del dominio.
Frecuencia de ejecución
Selecciona entre las opciones Diaria, Semanal o Mensual. De forma predeterminada la ejecución se encuentra configurada mensualmente.
URLs a excluir en el rastreo
Ingresa las URLs, dominios o subdominios que quieras excluir del rastreo separándolos con comas. Este campo es opcional, pero resulta útil si, por ejemplo, tu sitio web incluye un blog o rutas con información que no aporta conocimiento útil a tu chatbot. Esto podría generar información irrelevante al responder preguntas frecuentes de tus usuarios, además de consumir créditos.
Para un uso más óptimo del crawler te invitamos a leer sobre la optimización del uso de créditos
Para visualizar un recorrido del módulo de Crawler te compartimos el siguiente video.